On 19th January 2001, the new KEK central computer system started operation. In this system, we employed DCE/DFS [1] for user authentication and distributed file service, and HPSS [2] for data management. This combination answered the demands for better security and higher data transfer rate. The basic hardware configuration is shown in Figure 1.

- Figure 1 Overview of the KEK central computer system.
HPSS Data Server consists of IBM RS6000-SP, 7133 SSA Disks and 3590E tape drives in a 3494 tape library.
KEK has several computer systems in operation in the Computing Research Center. Each system services a particular group. i.e. the KEKB computer system is dedicated for BELLE, and the super computer system is mainly dedicated for the lattice QCD group. Among the systems, the central computer system has unique characteristics. The system is shared by many projects in KEK.
The system is designed to provide six workgroup services: PS experiments, JLC, ATLAS-Japan, neutron and meson study (NML), accelerator research and others. The current resource assignment is shown in Table 1.
In this paper, we will describe data management system, access methods, wrapper design, and benchmarking, in the following sections.
| WorkGroup | Calculation Server | Home directory | Tape Library |
|---|---|---|---|
| Central | 1561 SPECint95 | 255GB | 37.5TB |
| PS experiments | 683 SPECint95 | 255GB | 50TB |
| JLC experiments | 292 SPECint95 | 127GB | 2TB |
| ATLAS-Japan | 292 SPECint95 | 127GB | 10TB |
| NML | 97 SPECint95 | 127GB | 0.5TB |
| Accelerator | 195 SPECint95 | 127GB | 20TB |
| Total | 3120 SPECint95 | 1000GB | 120TB |
Because of high capacity demand on storage, i.e. 120TB, we could not afford to achieve it only with disks. We decided to use a hierarchical storage management system to use tapes and disks seamlessly. From the experience of the previous system, we learned the following points.
- Balancing performance among components is important. Even if the tape drive is very fast, the disk drive might degrade performance. Usually, many processes share disk drives as a cache, and migration-in and migration-out may happen at the same time. This means that one disk array should be at least twice as fast as one tape drive.
- Some HSM systems start real migration-out of files when data in the cache disk exceeds the high water mark. However, in this situation, the disk cache is very busy because of multiple accesses. The file should be copied to tapes regularly before reaching the high water mark. Only the purging of the cache disk and the update of meta data should happen when the high water mark is reached.
- For one disk cache space, multiple data drives should be attached as a pool.
- API access is mandatory to gain performance. NFS or other distributed file systems are not suitable for high-speed transfer.
Considering these points, HPSS was chosen as the data management system in the new central computer system.
As we have mentioned in the previous section, API access is mandatory to gain maximum performance. The HPSS client API is designed to perform best with very long record length, i.e. 1MB or more. Most users in the central computer system use 64KB or less, which is not suitable for gaining maximum performance on HPSS. To solve this, we built our own wrapper with a buffering mechanism.
We designed this wrapper for the HPSS client API as substitutes for system calls; open, read, write, close, seek and stat. Using the wrapper, users can simply replace the standard system calls with the wrapper calls. C language users can automatically use the wrapper by using preprocessors: including the header file in existing source code file.
As a reference of the implementation of the wrapper, ZEBRA [3], a part of the CERN library, was re-written to use the wrapper. PAW and other tools using the CERN library can be used to read and write data directly from HPSS. All of these programs can be used on the central computer system and as well as our own system connected to the LAN, i.e. PC Linux.
The benchmarking of the client API wrapper was done at IBM Poughkeepsie, using an RS/6000-SP with 17 POWER3 375MHz nodes, consisting of ten client nodes, six disk mover nodes and one core server node. The hardware configuration is shown in Figure 2. The software environment is HPSS R4.1.1, AIX V4.3.3, DCE V2.2 and Encina 4.2.
In the benchmark test, the I/O performance and CPU consumption rate on each client were measured. A single read and write process on ten clients concurrently get access to HPSS. Each process writes/reads a file of 4GB to/from an HPSS directory with a request size of data:64KB. This approach allows us to determine the I/O performance per process in the production system. The mean average of five benchmark runs is as below:
-
Average performance of read per client process: 31.6MB/second
Average performance of write per client process: 14.8MB/second
Average CPU usage rate per client: 16.4%
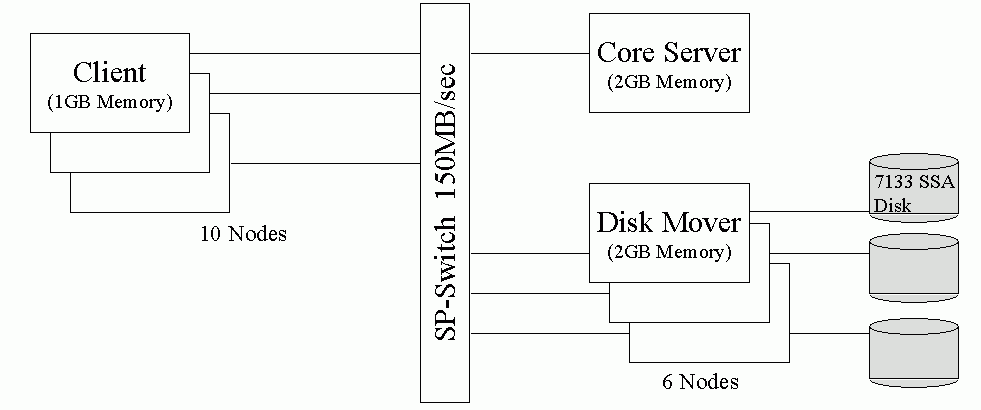
- Figure 2 Benchmarking environment of client API wrapper.
HPSS performance reached 464MB/second as an aggregate with six disk movers. This means that each disk mover approximately achieved 77MB/second.
HPSS solved the problems that existed in our previous system. In addition, we achieved a high data transfer rate by using the client API, which is available in Linux.
The use of the wrapper enabled us to modify our code to make use of the client API with ease. For example, the HPSS version of dd, tar and so on using the client API have been provided. The most significant example is PAW running on a Linux client, which manipulate the data in the HPSS.